The field of catalyst discovery plays a crucial role in various industries, from the production of everyday products like yogurt and Post-It notes to the development of sustainable energy sources. Traditionally, scientists have relied on laborious experiments and complex quantum chemistry calculations to identify optimal catalyst materials for specific reactions. However, in recent years, the emergence of machine learning approaches has revolutionized this process.
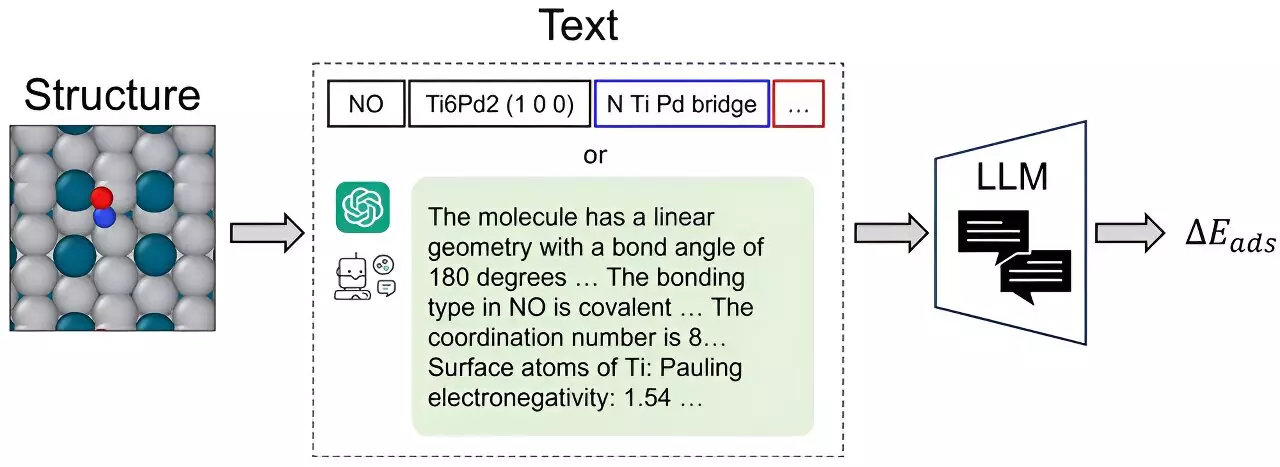
Researchers at Carnegie Mellon University’s College of Engineering have developed a groundbreaking approach called CatBERTa. This energy prediction Transformer model utilizes large language models (LLMs) to tackle molecular property prediction, offering a novel avenue for modeling in catalyst discovery. Led by Janghoon Ock, a Ph.D. candidate in Amir Barati Farimani’s lab, the team leverages CatBERTa’s ability to directly process text, eliminating the need for extensive preprocessing.
One significant advantage of CatBERTa is its human interpretability. By relying on natural language without additional preprocessing steps, researchers can seamlessly integrate observable features into their data. The self-attention scores provided by the transformer model contribute to enhanced comprehension within this framework. While Ock acknowledges that CatBERTa may not replace state-of-the-art graph neural networks (GNNs), he believes it can serve as a complementary approach, reinforcing the notion that “the more, the merrier.”
CatBERTa has demonstrated comparable predictive accuracy to earlier versions of GNNs, particularly when trained on limited-size datasets. Its impressive performance extends to surpassing the error cancellation abilities of existing GNNs. Although the team initially focused on adsorption energy, they envision expanding this approach to other properties, such as the HOMO-LUMO gap and stabilities related to adsorbate-catalyst systems, provided an appropriate dataset is available.
By harnessing language models’ capabilities and aligning them with the specific requirements of catalyst discovery, the CatBERTa team aims to streamline the catalyst screening process. Their ultimate goal is to expedite the identification of effective catalyst materials for various reactions, thus facilitating advancements across multiple industries. Ock continues to work diligently to further improve the accuracy of the CatBERTa model.
CatBERTa represents a groundbreaking approach towards catalyst discovery, bridging the gap between language models and molecular property prediction. Its unique ability to process text without extensive preprocessing sets it apart from traditional methods. While it may not replace established graph neural networks, CatBERTa offers a complementary approach that broadens the spectrum of possibilities in the field. With its superior predictive accuracy and potential for efficient catalyst screening, CatBERTa paves the way for accelerated progress in the industry, unlocking new frontiers in catalyst research and development.
Leave a Reply