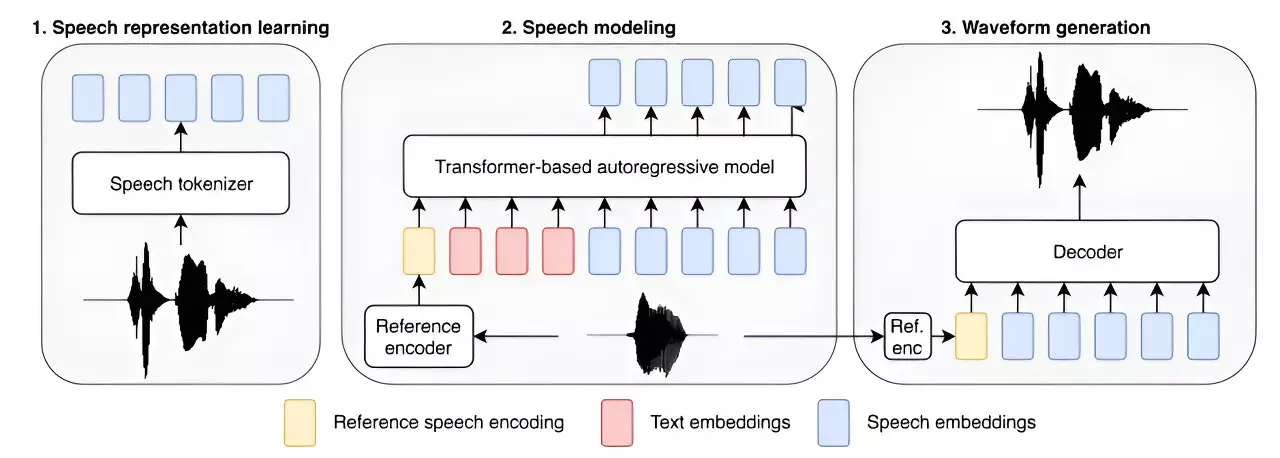
In a groundbreaking development, a team of researchers at Amazon AGI has unveiled the largest text-to-speech model ever created. This model, known as the Big Adaptive Streamable TTS with Emergent abilities (BASE TTS), boasts an impressive 980 million parameters and was trained on a massive dataset of 100,000 hours of recorded speech. The team’s efforts mark a significant milestone in the field of artificial intelligence, pushing the boundaries of what is possible with text-to-speech technology.
One of the key objectives of the researchers was to improve the language abilities of the text-to-speech application. By exposing the model to a diverse range of spoken words and phrases, including those from different languages, the team aimed to enhance its pronunciation accuracy and natural language processing capabilities. This approach ensures that the model can accurately articulate complex phrases such as “au contraire” and “adios, amigo,” demonstrating a high level of linguistic proficiency.
Through their research, the team at Amazon explored the concept of emergent qualities in AI applications. They observed that the BASE TTS model exhibited a significant leap in intelligence when trained on a medium-sized dataset of 150 million parameters. This leap involved the development of various language attributes, such as the use of compound nouns, expression of emotions, integration of foreign words, utilization of paralinguistics and punctuation, and formulation of questions with emphasis on specific words within a sentence.
Despite the impressive capabilities of the BASE TTS model, the researchers have chosen not to release it to the public due to ethical concerns regarding potential misuse. Instead, they plan to leverage the model as a learning tool to further enhance the human-like quality of text-to-speech applications in a responsible manner. By building upon their current findings, the team aims to continually advance the state of text-to-speech technology, ultimately delivering more sophisticated and natural-sounding speech synthesis solutions for a wide range of applications.
Leave a Reply