Large language models (LLMs) have been making waves in the tech world, with their ability to comprehend written prompts and generate responses that closely resemble human speech. But just how realistic are these generated texts? A recent study conducted by researchers at UC San Diego set out to answer this question by running a Turing test, a method designed to evaluate a machine’s demonstration of human-like intelligence. The results, which were outlined in a paper pre-published on the arXiv server, revealed that people found it challenging to differentiate between the GPT-4 model and a human agent during 2-person conversations.
The initial study conducted by Jones and Bergen, a Prof. of Cognitive Science at UC San Diego, produced intriguing results, suggesting that GPT-4 could successfully pass off as human in approximately 50% of interactions. However, the experiment lacked proper controls for variables that could impact the findings. This led the researchers to conduct a second experiment, which ultimately provided more insightful results and formed the basis of their recent paper.
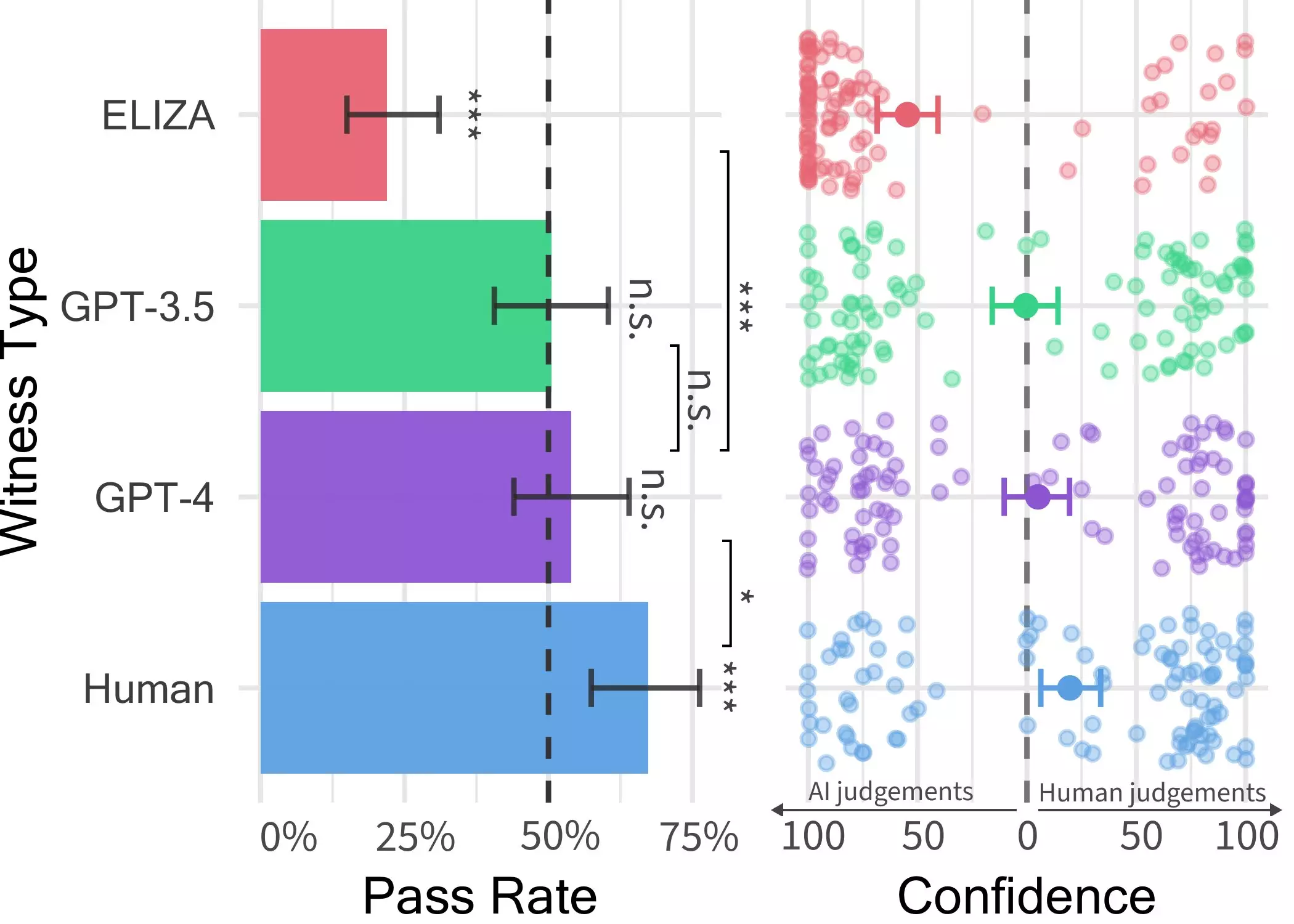
During the experiments, participants engaged in a two-player online game, where they interacted with a “witness” – either a human or an AI agent. The interrogator asked the witness a series of questions to determine whether it was human or not. These conversations could last up to five minutes, during which participants could discuss any topic, except for using abusive language, which was filtered out.
In this game scenario, the researchers utilized three LLMs as potential witnesses: GPT-4, GPT 3.5, and the ELIZA models. Surprisingly, users could often discern that the ELIZA and GPT-3.5 models were machines. However, when it came to determining if GPT-4 was a human or a machine, their success rate was no better than random chance. This finding indicates that distinguishing between GPT-4 and humans in real-world interactions might prove to be quite challenging for individuals.
The outcomes of the Turing test underscore the increasingly thin line between human and AI interactions. As LLMs, especially GPT-4, become more adept at mimicking human speech, there arises a concern regarding the trustworthiness of online communications. The researchers plan to update and reintroduce the public Turing test to investigate additional hypotheses. By exploring new avenues, they aim to gain further insights into people’s ability to differentiate between humans and LLMs.
The study conducted at UC San Diego sheds light on the deceptive nature of large language models, particularly the GPT-4 model. As these models blur the lines between human and machine interactions, the implications for the future of AI applications in client-facing roles and misinformation campaigns are significant. By continuing to push the boundaries of Turing tests and similar experiments, researchers can uncover valuable information about the evolving relationship between humans and AI systems.
Leave a Reply