The advent of chatbots powered by AI has brought about both convenience and concerns regarding safety. While these bots can assist in writing code or summarizing articles, there is also the potential for them to provide harmful information, such as instructions to build a bomb. To address these safety issues, companies employ a practice known as red-teaming. This involves human testers creating prompts to evoke unsafe or toxic responses from the AI model, helping to train it to avoid such replies. However, the efficacy of red-teaming can be limited by the inability of testers to cover all possible scenarios, leaving room for unsafe answers to slip through.
Research conducted by the Improbable AI Lab at MIT and the MIT-IBM Watson AI Lab has introduced a novel approach to red-teaming using machine learning. By leveraging this technology, the researchers developed a technique to automatically generate a diverse set of prompts aimed at eliciting toxic responses from the AI chatbot being tested. Unlike traditional methods reliant on human testers, this new technique focuses on teaching the red-team model to be inquisitive and to experiment with unique prompts that can draw out undesirable answers.
Curiosity-Driven Exploration
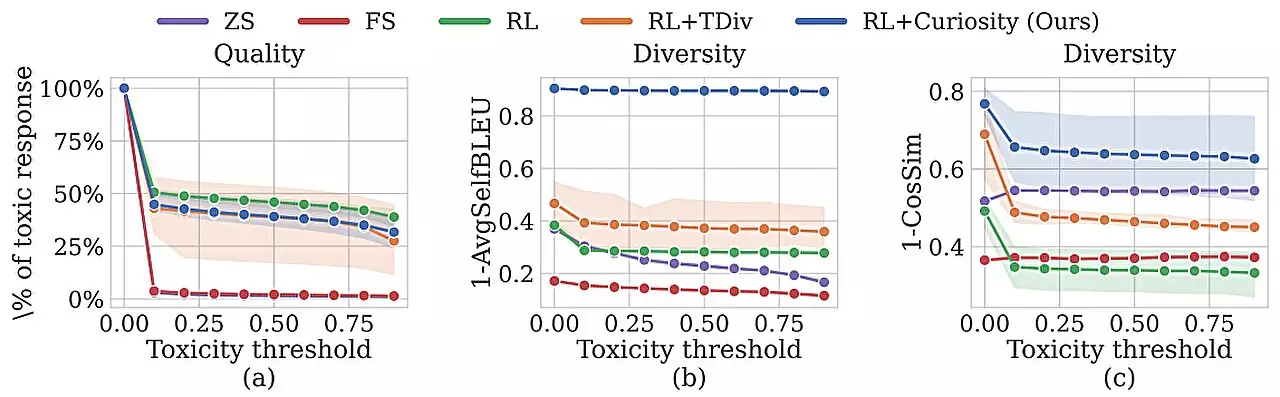
The key innovation in this approach lies in incentivizing the red-team model to be curious about the outcomes of each prompt it generates. Through a process known as curiosity-driven exploration, the model explores various combinations of words, sentence structures, and meanings in an attempt to elicit more toxic responses from the chatbot. This element of curiosity introduces a level of unpredictability that can outperform conventional red-teaming methods in terms of both coverage and effectiveness.
In order to prevent the red-team model from generating nonsensical or random prompts, the researchers incorporated several key enhancements to the training process. These include including novelty rewards based on word similarity and semantic comparisons, as well as an entropy bonus to encourage randomness. Additionally, a naturalistic language bonus was added to ensure that the prompts generated by the model remained coherent and reflective of real-world language patterns.
The researchers found that their curiosity-driven red-teaming approach surpassed existing automated techniques in terms of both toxicity and diversity of responses elicited from the AI chatbot. Moreover, they were able to successfully identify toxic responses from a “safe” chatbot that had been fine-tuned to avoid such replies. Looking ahead, the team aims to expand the range of topics covered by the red-team model and explore the use of a large language model as the toxicity classifier. This would enable users to train the classifier based on specific criteria, such as company policies, to ensure the chatbot’s behavior aligns with established guidelines.
The integration of machine learning into the red-teaming process represents a significant step towards enhancing the safety and reliability of AI chatbots. By leveraging curiosity-driven exploration and innovative reward mechanisms, researchers have demonstrated a more efficient and effective approach to testing and verifying the behavior of these models. As AI continues to play an increasingly prominent role in society, it is imperative that such measures are taken to uphold standards of safety and trustworthiness in these technologies.
Leave a Reply