Artificial intelligence (AI) has been revolutionizing various industries, from self-driving cars to content creation and medicine. However, one major challenge in developing AI models is the presence of data biases, which can lead to inaccurate results. Professor Sang-hyun Park and his research team at Daegu Gyeongbuk Institute of Science and Technology (DGIST) have made a significant breakthrough in this area by developing a new image translation model that effectively reduces biases in data.
When training deep learning models using datasets collected from different sources, biases can occur due to various factors. For example, when creating a dataset to distinguish between bacterial pneumonia and COVID-19, variations in image collection conditions may lead to subtle differences in the images. As a result, existing deep learning models may focus on features stemming from image protocols rather than the critical characteristics for practical disease identification. This limitation can cause over-fitting issues and lead to inaccurate predictions.
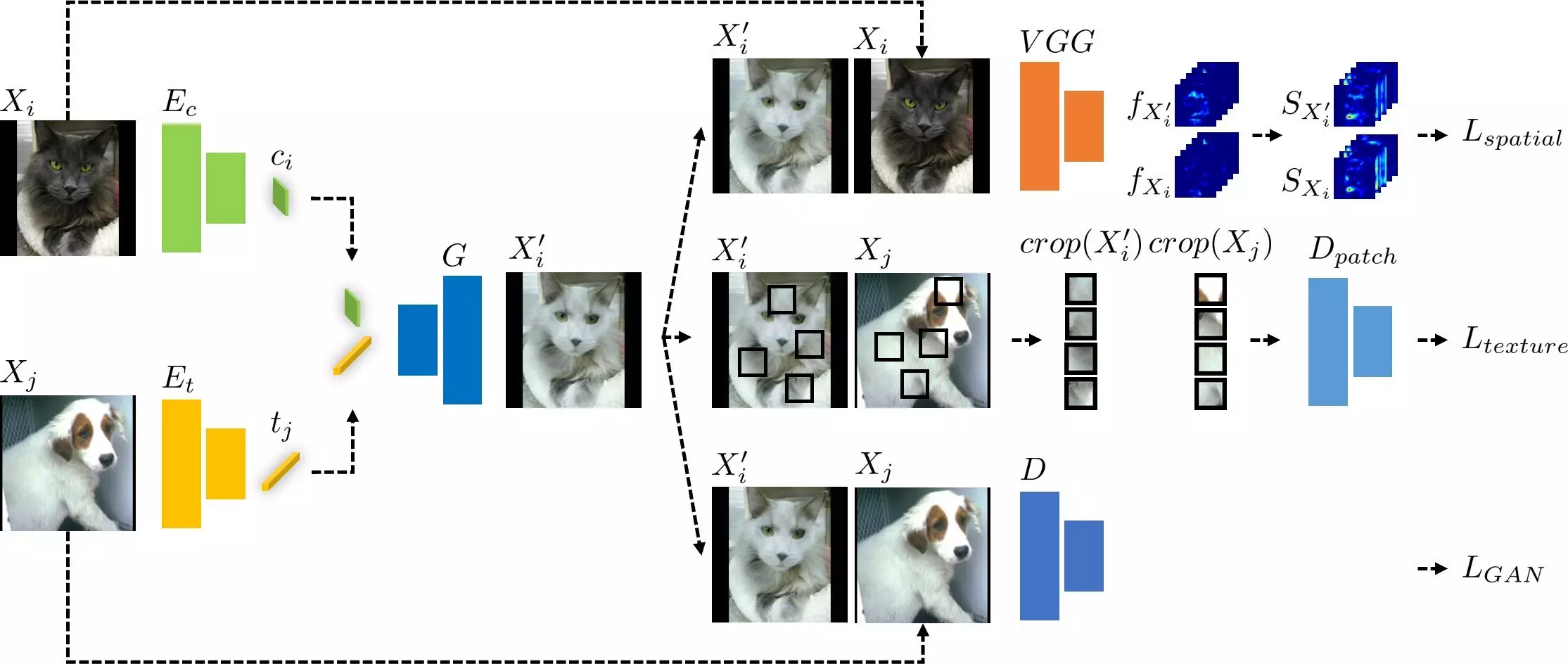
To address the challenges posed by data biases, Prof. Park’s research team developed an image translation model that applies texture debiasing to generate a dataset for training deep learning models. Unlike existing models, which often struggle with unintended content alterations when altering textures, this new model simultaneously considers error functions for both textures and contents.
The developed image translation model works by extracting information on the contents of an input image and textures from a different domain, and combining them. By training the model using error functions for spatial self-similarity and texture co-occurrence, it can generate an image that retains the contents of the original image while applying the texture of the new domain. This approach not only reduces biases but also maintains the integrity of the input image.
The performance of the developed deep learning model surpasses that of existing debiasing and image translation techniques. It outperforms existing methods when tested on datasets with texture biases, such as classification datasets for distinguishing numbers and different hair colors in dogs and cats. It also demonstrates superior performance on datasets with various biases, including those for distinguishing multi-label numbers and different types of visual content.
Aside from its applications in image translation, the technology developed by Prof. Park’s research team can also be implemented in image manipulation. The team found that the new method alters only the textures of an image while preserving its original contents, showcasing its superiority compared to existing image manipulation methods. Furthermore, this solution is effective in other environments, as demonstrated by its performance on various domains such as medical and self-driving images.
With the development of this new image translation model, Prof. Park and his research team have made a significant contribution to the field of AI by addressing data biases in deep learning models. By effectively reducing biases and improving performance, this breakthrough has the potential to revolutionize industries such as self-driving, content creation, and medicine. As further advancements are made in this area, we can expect even more accurate and reliable AI models that transform the way we live and work.
Leave a Reply