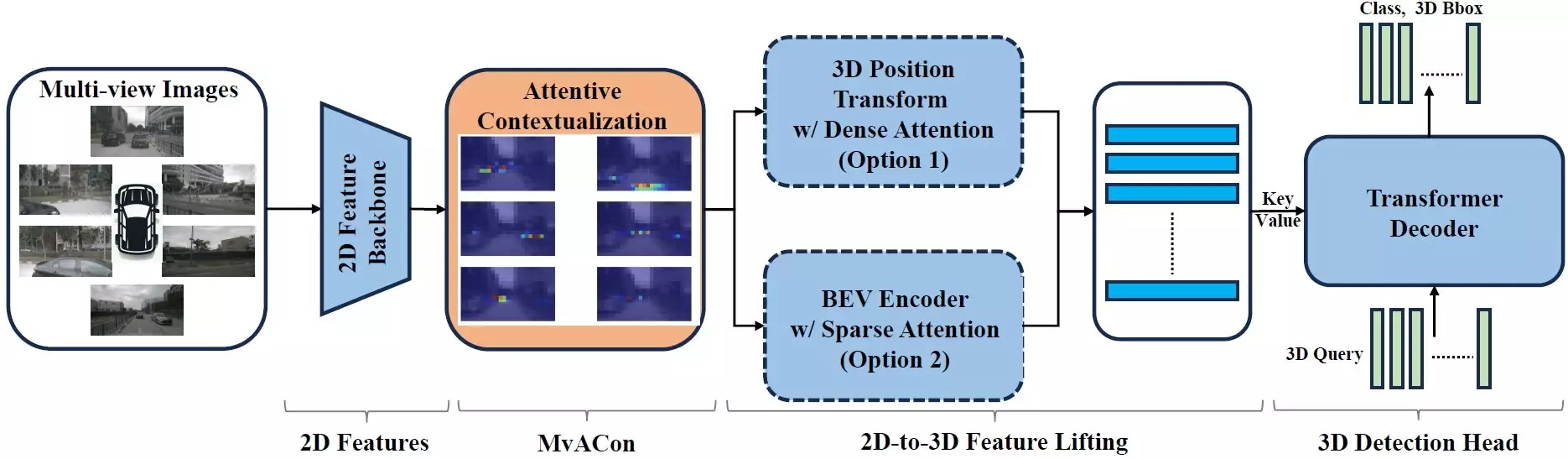
Advancements in artificial intelligence (AI) technology have paved the way for innovative techniques to enhance the capabilities of autonomous vehicles. One such technique, known as Multi-View Attentive Contextualization (MvACon), has shown great promise in improving the mapping of three-dimensional spaces using two-dimensional images captured by multiple cameras. This development, led by researchers at North Carolina State University, offers a new approach to optimizing the navigation of autonomous vehicles and enhancing their object detection capabilities.
MvACon builds upon the foundation of Patch-to-Cluster attention (PaCa), a concept introduced by the research team led by Tianfu Wu. PaCa enables transformer AIs to identify objects within images more effectively and efficiently. By incorporating PaCa into the challenge of mapping 3D space using data from multiple cameras, MvACon introduces a novel framework for improving the performance of existing vision transformer AIs. This supplemental technique does not require additional data but rather enhances the utilization of existing information to create a more accurate representation of the surrounding environment.
The key objective of MvACon is to augment the capabilities of vision transformers in mapping 3D spaces and detecting objects within these spaces. Through experiments utilizing leading vision transformers such as BEVFormer, BEVFormer DFA3D variant, and PETR in conjunction with MvACon, researchers observed significant improvements in object localization, speed, and orientation detection. The integration of MvACon with these vision transformers resulted in enhanced performance without imposing a substantial increase in computational demands. This successful implementation underscores the potential of MvACon in advancing the field of autonomous navigation and object detection.
The potential applications of MvACon extend beyond the laboratory setting, with researchers planning to test the technique across diverse benchmark datasets and real-world scenarios involving video input from autonomous vehicles. By evaluating the performance of MvACon in comparison to existing vision transformers, researchers aim to assess its viability for widespread adoption. The upcoming presentation of the research paper at the IEEE/CVF Conference on Computer Vision and Pattern Recognition in Seattle, Washington, signifies the continued exploration of MvACon’s capabilities by the scientific community.
The development of Multi-View Attentive Contextualization represents a significant milestone in the field of AI-driven navigation and object detection. By leveraging innovative techniques such as PaCa and incorporating them into the mapping of 3D spaces using multiple cameras, researchers have demonstrated the potential for enhancing the performance of autonomous vehicles. The successful integration of MvACon with leading vision transformers underscores its efficacy in improving object detection and spatial mapping capabilities. As further research and testing are conducted, MvACon holds the promise of revolutionizing the landscape of autonomous navigation technologies.
Leave a Reply