In the realm of deep learning, training models on expansive datasets is undeniably crucial for success. However, these datasets often harbor label noise, which can severely undermine the accuracy of the model when it comes to classification tasks. This issue has garnered increasing attention among researchers, as label noise can lead to considerable declines in the performance of deep learning models, especially during testing phases. The challenge lies not only in the presence of noise but also in its complexity, as the extent and type of noise can vary greatly across different datasets.
To tackle the issue of label noise, a research team from Yildiz Technical University, consisting of Enes Dedeoglu, H. Toprak Kesgin, and Prof. Dr. M. Fatih Amasyali, has introduced an innovative solution known as Adaptive-k. This newly developed method aims to optimize the training process and enhance model performance even in the presence of noisy labels. Their findings were disseminated in the journal Frontiers of Computer Science, marking a significant step forward in the field of machine learning.
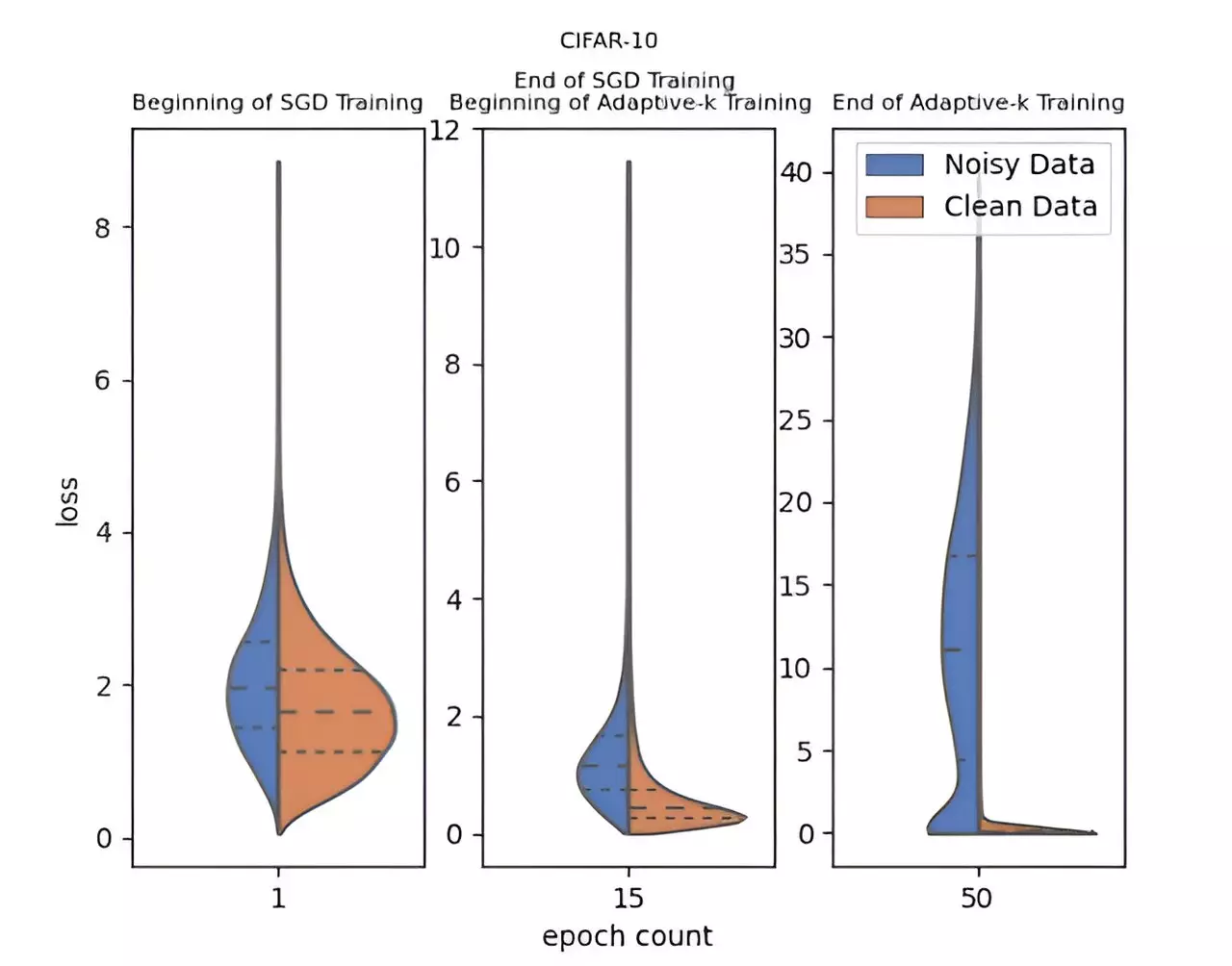
What sets the Adaptive-k method apart is its adaptive capability to determine the optimal number of samples to select from the mini-batch for model updates. This leads to a more precise differentiation between clean data and noisy samples, thereby augmenting the overall effectiveness of training. Unlike many existing methods, Adaptive-k is lauded for its simplicity and effectiveness, as it circumvents the need for prior information regarding the dataset’s noise ratio and eliminates the necessity for excessive training time or extra model training.
In rigorous testing, the Adaptive-k method showcased a remarkable ability to approach the performance benchmarks established by the Oracle method, which involves the complete exclusion of known noisy samples. The research team undertook comparative evaluations of Adaptive-k against several well-known algorithms, including Vanilla, MKL, Vanilla-MKL, and Trimloss. They meticulously tested the algorithm on three image datasets and four text datasets, and the results were telling: Adaptive-k consistently outperformed its counterparts in managing label noise.
Moreover, one of the notable features of Adaptive-k is its compatibility with multiple optimization techniques, including Stochastic Gradient Descent (SGD), Stochastic Gradient Descent with Momentum (SGDM), and Adam. This adaptability ensures greater versatility across various applications, making the method applicable to a wide spectrum of deep learning scenarios.
The contributions of this research extend beyond the mere introduction of the Adaptive-k method. With a theoretical analysis that compares Adaptive-k with established algorithms such as MKL and SGD, the study provides valuable insights into noise estimation without prior dataset knowledge or hyperparameter adjustments. Furthermore, the empirical results bolster the case for Adaptive-k’s effectiveness in enhancing deep learning training on noisy datasets.
Looking ahead, the research team aims to refine Adaptive-k further and explore additional applications across diverse datasets. The ongoing enhancement of this method promises to not only advance the realm of deep learning but also to set a new standard for handling the pervasive issue of label noise.
Leave a Reply