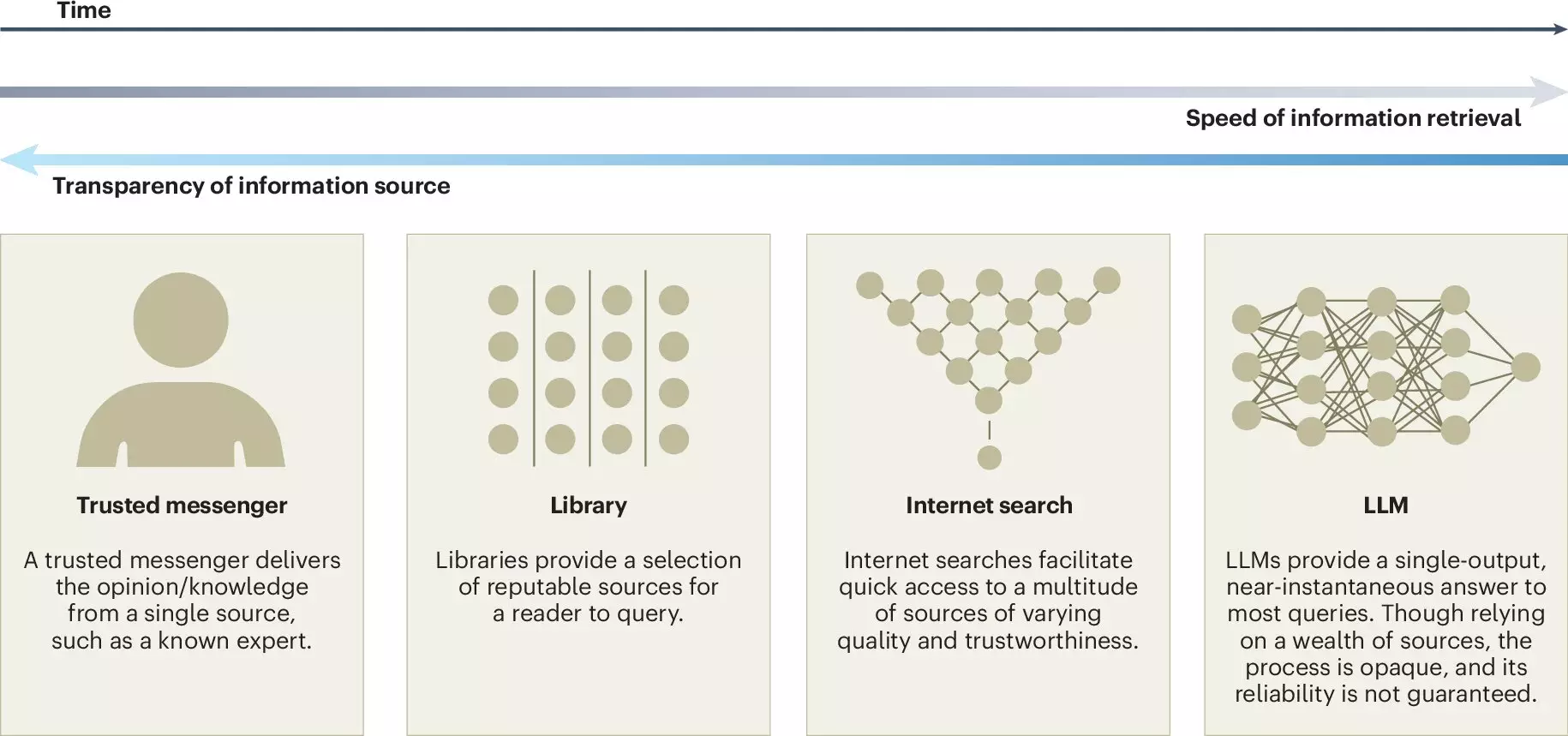
The rapid rise of large language models (LLMs) has significantly transformed various aspects of our daily interactions. These sophisticated artificial intelligence systems, epitomized by applications such as ChatGPT, analyze vast datasets to generate human-like text. While LLMs present compelling opportunities to enhance communication and decision-making processes, they also pose considerable risks to collective intelligence—the combined intellectual resources of individuals working together. A recent study published in Nature Human Behaviour, steered by experts from Copenhagen Business School and the Max Planck Institute for Human Development, sheds light on this complex dilemma, urging society to navigate the evolving landscape of LLMs with caution and foresight.
Collective intelligence refers to the phenomenon where a group of individuals can pool their insights and knowledge to achieve superior outcomes than individuals acting independently. This concept plays a crucial role in various settings, from dynamic workplaces to collaborative platforms like Wikipedia. By harnessing diverse perspectives, groups can overcome cognitive limitations inherent in individual thinking. As we increasingly lean on technology to facilitate these collaborations, understanding the interplay between collective intelligence and LLMs becomes essential. When faced with unfamiliar terms or complex topics, many of us instinctively turn to search engines or forums for collective input, highlighting our reliance on shared knowledge.
The potential advantages of integrating LLMs into collective decision-making processes are substantial. Among these benefits is their capacity to enhance accessibility during discussions. For instance, LLMs can assist in translation, allowing participants from various linguistic backgrounds to engage equally. Moreover, they serve as valuable tools in synthesizing information, summarizing diverse viewpoints, and streamlining idea generation. Ralph Hertwig, a leading voice in this study, points out that these capabilities could significantly enrich our collective dialogues and improve the quality of decisions made by groups.
LLMs also have the potential to provide real-time assistance in formulating opinions and identifying common ground. By analyzing the prevailing narratives surrounding an issue, these models can expedite consensus-building endeavors. In environments where information overload is common, LLMs can efficiently distill critical viewpoints, fostering a more focused and productive discussion.
However, the enthusiasm surrounding LLMs must be tempered with a keen awareness of their limitations and associated risks. One major concern is the possibility of diminishing individuals’ motivation to contribute to communal knowledge bases like Wikipedia. If users become overly reliant on LLM-generated content, the value of original contributions could be jeopardized, eventually leading to a homogenized pool of knowledge lacking in diversity and nuance.
Another significant risk highlighted in the study is the potential for fostering false consensus. The way LLMs aggregate information could create misleading impressions of majority opinions. As Jason Burton points out, the training data for these models might not adequately represent minority viewpoints, leading to an illusion of widespread agreement on specific matters. This phenomenon could marginalize essential perspectives, reinforcing existing biases and compromising genuine deliberation.
In light of these complexities, the study emphasizes the need for greater transparency in the development of LLMs. Researchers advocate for clear disclosures regarding the sources of training data and the mechanisms for creating these models. By instituting external audits and monitoring, developers can be held accountable, ensuring that LLMs contribute positively to collective intelligence rather than undermine it.
Importantly, the article underscores the role of humans in shaping LLMs. It argues that achieving diverse representation in training data is essential to preventing knowledge homogenization. Providing compact informational resources related to LLMs can foster a better understanding of their implications on collective intelligence. Topics such as the ethical considerations around co-created outcomes deserve particular attention as society navigates this evolving landscape.
As society increasingly integrates LLMs into the fabric of communication and decision-making, it becomes paramount to consider both their potential for enhancement and the risks they pose. The key takeaway from the collaborative research is the imperative for proactive measures that prioritize transparency, diversity, and accountability in the development of these powerful technologies. Future research must delve deeper into the implications of LLMs on collective intelligence, addressing critical questions regarding credit and responsibility when outcomes hinge on machine-human collaboration. By adopting a nuanced and reflective approach, we can better harness the transformative power of LLMs while safeguarding the integrity of our collective intelligence.
Leave a Reply